
PhD Student
CSIRO Data61
UOW AMRL VILA
School of Computing & IT
University of Wollongong
Current Office:
Room No. 3.237, Building 3
UOW Wollongong Campus
Contact me:
1 sr801uowmail.edu.au
2 saimun.rahmandata61.csiro.com
(+61) 4 1374 0811
Find me on :
•
•
•
•
Image and Video Recognition in the Wild
Although image and video recognition systems have achieved impressive performance in recent years, their use in real-world applications remains challenging, especially when the image and videos are captured under non-ideal conditions, as is common in surveillance-based and machine vision based applications. Images and videos captured in such circumstances are often contaminated by blur, non-uniform lighting, low quality, and low inter-class difference. My research addresses these problems and proposes solutions to enable image and video recognition in real-world applications (in the wild) with high precision.
My work focuses on the extraction of effective and efficient features from images and videos. My works are in the areas of Computer Vision, Pattern Recognition and Machine Learning. My contributions are mostly in the field of deep covariance-matrix based feature learning, fine-grained image recognition, spatio-temporal data analysis, texture classification, and action recognition in low quality videos.
My works can be divided into three groups based on their types:
Medical images classification is a significant research area that receives growing attention from both the research community and medicine industry. It addresses the problem of diagnosis, analysis and teaching purposes in medicine. One of the primary objective of medical images classification is not only to achieve good accuracy but to understand which parts of anatomy are affected by the disease to help clinicians in early diagnosis of the pathology and in learning the progression of a disease. My work focuses on the understanding of medical images and perform their accurate classification with advance machine learning models.
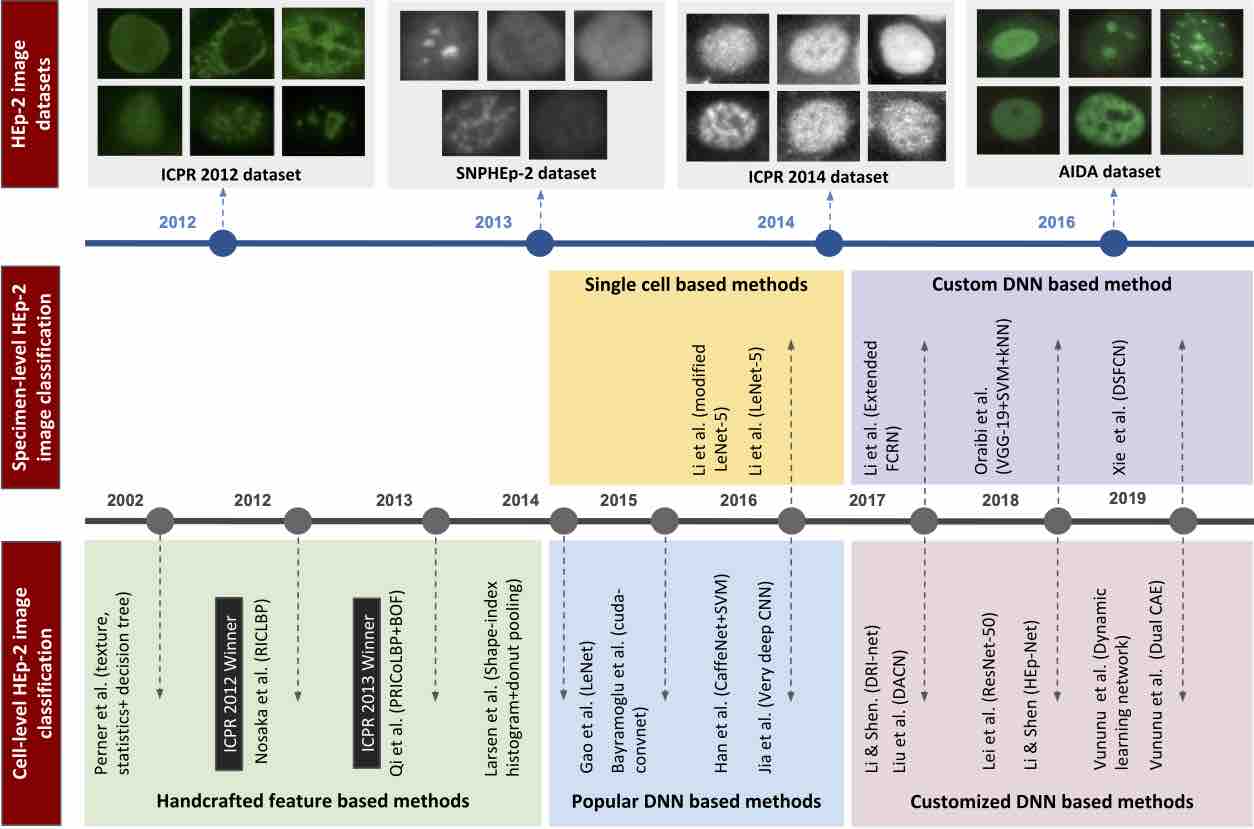
Deep Learning based HEp-2 Image Classification: A Comprehensive Review
Saimunur Rahman, Lei Wang, Changming Sun, Luping Zhou
Medical Image Analysis (2020):101764.
Fine-grained Image Recognition
The general object classification task distinguishes very different object categories, such as a house and a bird. In contrast, fine-grained image classification aims to answer the question of given a bird image: which bird species is it? In a more specific way, it is about species and sub-category classification. This is a challenging task for two reasons. Firstly, some classes (species) from the same category, such as fish, have a very similar appearance leading to low inter-class variation. Secondly, a high degree of variability is prone to occur even within the same class due to large pose, lighting, and illumination variations in the natural environment. My research explores methods to improve fine-grained classification in challenging general and medical image datasets.
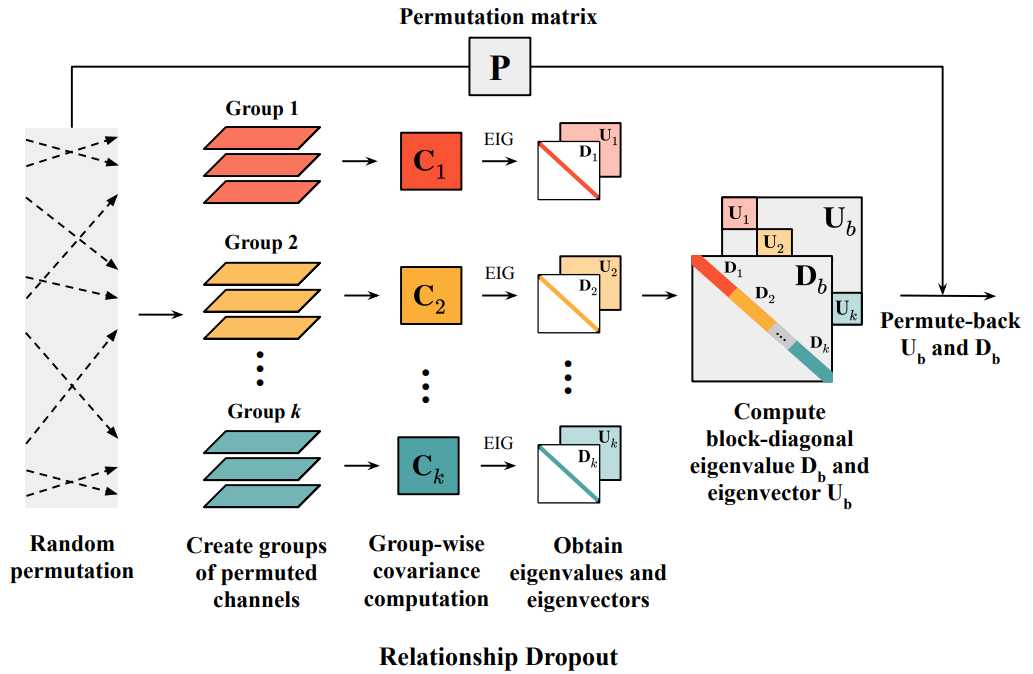
ReDro: Efficiently Learning Large-sized SPD Visual Representation
Saimunur Rahman, Lei Wang, Changming Sun, Luping Zhou
European Conference on Computer Vision (ECCV), UK, 23-28 August 2020.
While human inspectors working on assembly lines visually inspect parts to judge the quality of workmanship, machine vision systems use cameras and image processing software to perform similar inspections. Machine Vision inspection plays an important role in achieving 100% quality control in manufacturing, reducing costs and ensuring a high level of customer satisfaction. Machine vision system inspection consists of narrowly defined tasks such as counting objects on a conveyor, reading serial numbers, and searching for surface defects. Manufacturers often prefer machine vision systems for visual inspections that require high speed, high magnification, around-the-clock operation, and/or repeatability of measurements.
Following are some key projects in which I was involved during my tenure at Vitrox Corporation. Note that due to commercial reasons most of the findings in these projects were never published or demoed in front of the public.


Learning Convolutional Filter Kernels using ICA for Effective Gold Finger Defect Inspection
Saimunur Rahman, Ooi Song Wah and Goh Ken Onn
Vitrox Corporation Berhad, Penang, Malaysia

An Unsupervised Learning Approach for SSD Defect Detection
Saimunur Rahman and Ooi Song Wah
Vitrox Corporation Berhad, Penang, Malaysia

Learning ro Model Part Samples for Improved Defect Detection in Metallic Surface
Saimunur Rahman and Ooi Song Wah
Vitrox Corporation Berhad, Penang, Malaysia

cBSIF: Circular Binarized Statistical Image Features for Machine Vision Defect Inspection
Saimunur Rahman and Ooi Song Wah
Vitrox Corporation Berhad, Penang, Malaysia

Walk in the line: A low cost 2D fringe-pattern projected image defect analysis algorithm
Saimunur Rahman, Chung Wai Loong, and Ooi Song Wah
Vitrox Corporation Berhad, Penang, Malaysia
A Fast and Accurate Circle Estimation Algorithm for Machine Vision Inspections
Saimunur Rahman, Chung Wai Loong, and Ooi Song Wah
Vitrox Corporation Berhad, Penang, Malaysia
Action Recgnition in Low Quality Videos
Human action recognition (HAR) in video is presently one of fastest growing areas in computer vision research due to the ubiquity and abundance of video data. With the society's increasing awareness for personal safety, the need for better security in public spaces has heightened the importance of automated video surveillance, especially recognising human activities, events or interactions. In recent years, most state-of-the-art techniques for HAR have been designed to perform well under constrained and highly controlled conditions, with many producing high accuracies in good quality videos. These capabilities may not be easily replicable in real-world surveillance conditions (via devices such as CCTV or web cameras) where video quality may be naturally poor.
This research was aimed to investigate the visual recognition of human activities in low quality surveillance videos. Hence, the first crucial task involves examining feasible fundamental representations that utilize spatio-temporal information inherent in videos. Currently, spatio-temporal information (in the form of volumes, trajectories, local features) possesses various notable drawbacks in real-world surveillance videos. Meanwhile, the sensitivity of existing state-of-the-art methods towards video quality demands for the proposal of new learning models that can robustly characterize human activities under such conditions. The effectiveness and robustness of the proposed methods will be evaluated in benchmark surveillance datasets with uncontrolled, low quality video scenes. There is currently no systematic, extensive work analysing this problem domain relating to video quality. Various techniques have been proposed to tackle various poor video quality problems for effective action recognition. Following are the outcomes from this research:

Human Activity Recognition in Low Quality Videos Using Spatio-Temporal Features
M.Sc. (by Research) thesis, Supervisors: Dr. John See and Dr. Chiung Ching Ho
Multimedia University, Cyberjaya, June 2016
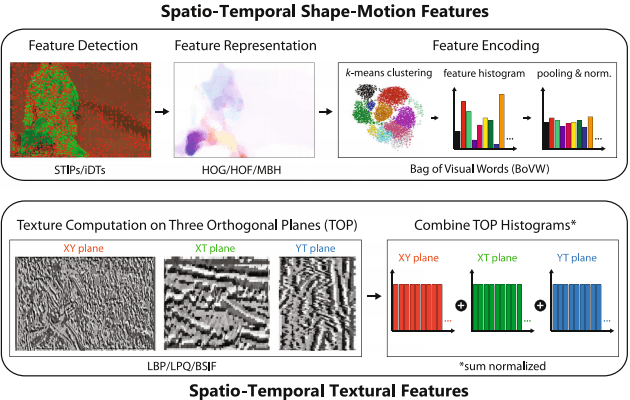
Exploiting textures for better action recognition in low-quality videos
Saimunur Rahman, John See and Chiung Ching Ho
EURASIP Journal on Image and Video Processing, 2017(1), p.74.
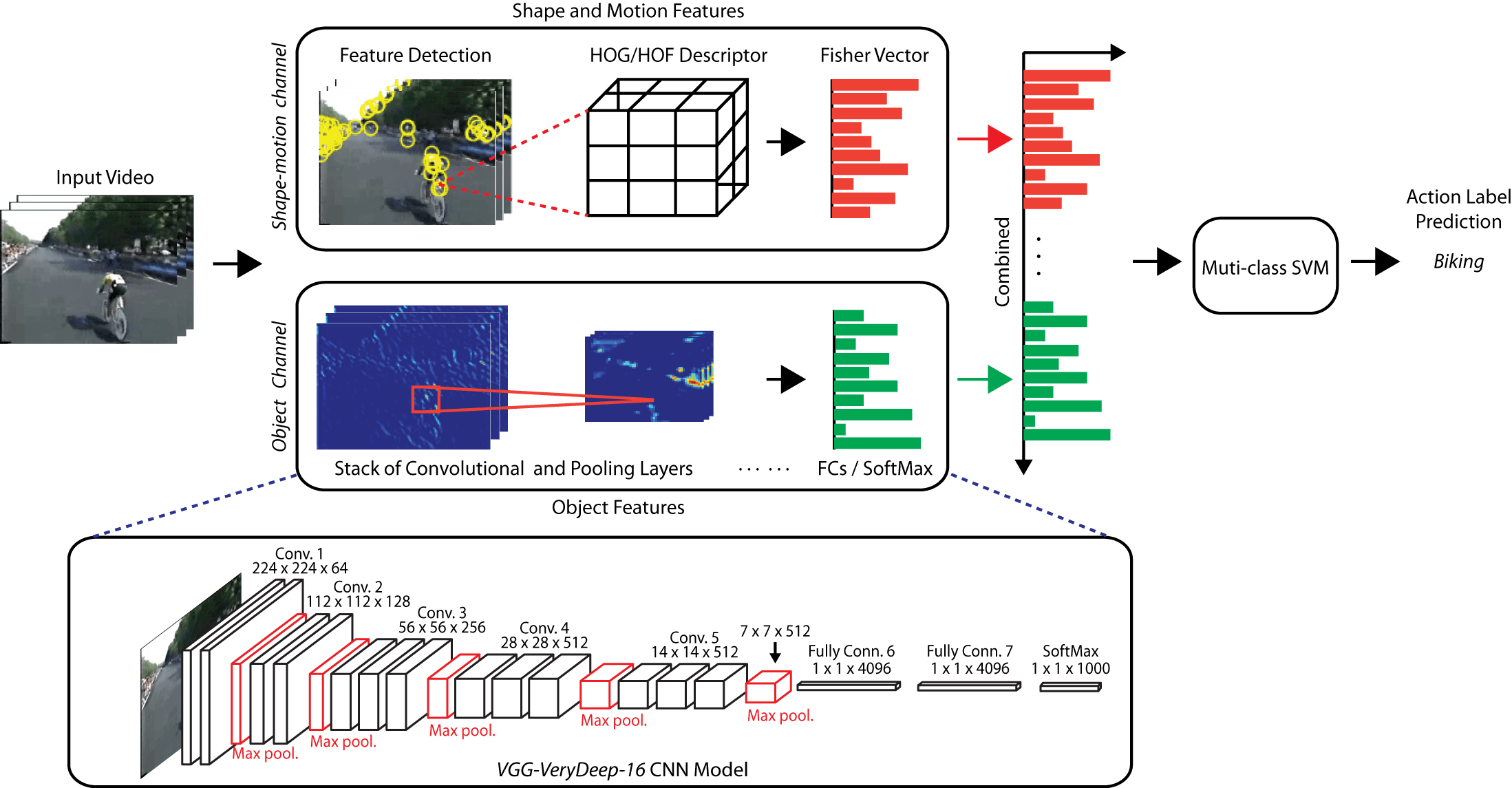
Deep CNN Object Features for Improved Action Recognition in Low Quality Videos
Saimunur Rahman, John See and Chiung Ching Ho
Advanced Science Letters, 23(11), pp.11360-11364
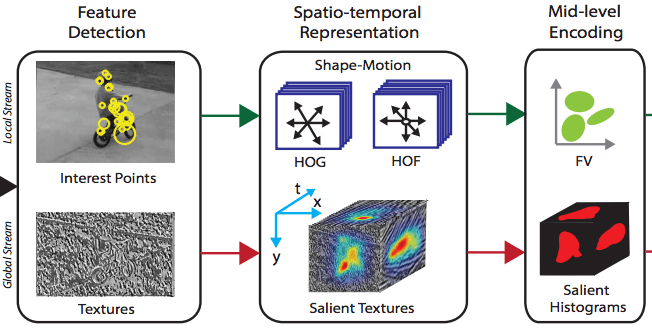

Leveraging Textural Features for Recognizing Actions in Low Quality Videos
Saimunur Rahman, John See and Chiung Ching Ho
International Conference on Robotics, Vision, Signal Processing & Power Applications (ROVISP), February 2-3, Penang, Malaysia, 2016


Action Recognition by Jointly using Shape, Motion and Texture Features in Low Quality Videos
Saimunur Rahman, John See and Chiung Ching Ho
IEEE International Conference on Signal and Image Processing Applications (ICSIPA), October 19-21, Kuala Lampur, Malaysia, 2015
Copyright notice: This material is presented to ensure timely dissemination of scholarly and technical work. Copyright and all rights therein are retained by authors or by other copyright holders. All persons copying this information are expected to adhere to the terms and constraints invoked by each author's copyright. These works may not be reposted without the explicit permission of the copyright holder.
© 2018 Saimunur Rahmnan. CC-NC-SA-4.0. Built with Bootstrap v3.3.6. Style adopted from Animesh Garg.